Beyond the Standard Assumptions in Reinforcement Learning
Reward Trajectory Feedback.
Overview
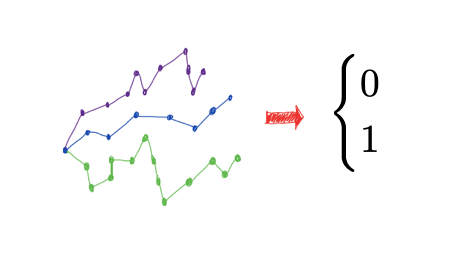
We study a theory of reinforcement learning (RL) in which the learner receives binary feedback only once at the end of an episode. While this is an extreme test case for theory, it is also arguably more representative of real-world applications than the traditional requirement in RL practice that the learner receive feedback at every time step. Indeed, in many real-world applications of reinforcement learning, such as self-driving cars and robotics, it is easier to evaluate whether a learner’s complete trajectory was either “good” or “bad,” but harder to provide a reward signal at each step. To show that learning is possible in this more challenging setting, we study the case where trajectory labels are generated by an unknown parametric model, and provide a statistically and computationally efficient algorithm that achieves sub-linear regret. We also study the corresponding Dueling Reinforcement Learning setting where the learner’s feedback comes in the form of noisy binary comparisons between trajectories.
Papers
Aldo Pacchiano
Eric and Wendy Schmidt Center Fellow / Faculty
My research interests include online learning, Reinforcement Learning, Deep RL and Fairness.